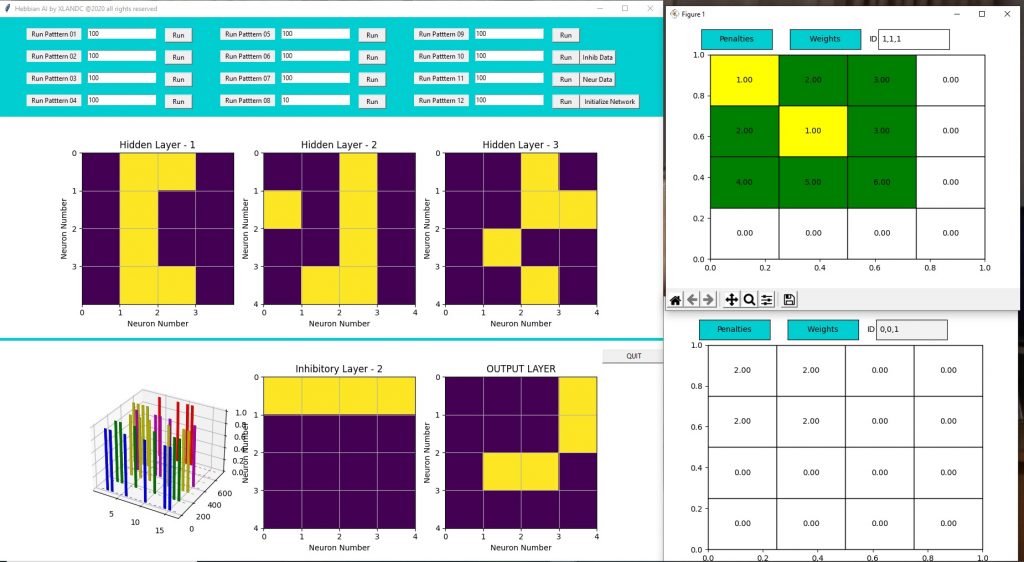
First of all, that’s my current setup, nothing fancy.
Second, I have made some progress but it’s uncertain. I don’t really have clear criteria for determining good/bad, am I going in a good direction or is it all bad.
About inhibitory neurons… My model failed in many ways and I concluded that maybe the biological model was not so bad after all. My inhibitory synapse kept being removed from all neurons after a while because with it in place nothing would work.. So neurons do help other neuron escape inhibition 😀 ….. to my astonishment..
I figured that a solution to my problem with neuronal reach could be (possibly should be) the orientation columns seen in biology. That’s where I’m going now. The feed-back issue is on ice for now, still have to solve other problems first.
What I call a computational cell is made up of 4 normal neurons governed by an inhibitory neuron as shown in my previous post. Now I increased the number of computational cells to 4 and everything became a big mess… Some neurons are now part of up to 4 cells… or 2.. or 3.. As synapses are further away from the neuron body, their contribution to the overall potential (activation potential), decreases. So the more synapses on a single neuron the more complexity resulting in a poor understanding of what’s going on and adjusting/optimizing the algorithms 🙁
Still some cell behave more or less predictable, predictable enough to realized that I have an additional problem, which I predicted, but I was hoping it will get somehow solved by the added complexity, something that I could not predict, but I could observe when actually running the full network. It did not happen. Far away patterns cannot connect to each other because I don’t have a fully connected network, neurons bind only in a limited area around their position (in the matrix) .Moreover things that worked on a single computational cell, such as a single neuron responding to all vertical lines, do not work among multiple computational cells. Last problem that I encountered is that now, the network, has become visible slower and I only have 128 neurons running wild… That’s because I’m forming now, tones of dendrites to respond to various patterns or perhaps there is something wrong within my latest modifications some wild loops working for no reasons… doesn’t bode well for the future though…
Overall I’d say I’m stuck with no clear way going forward.
Why am I writing this blog ? Because nobody is reading it 🙂 Well I write because by doing so I’m usually clarifying some thing in my head, sometimes laying out the problem clearly is a big step forward . For the same reasons I also speak to my friends about AI. I’m such a bore, I can tell you that much 🙂
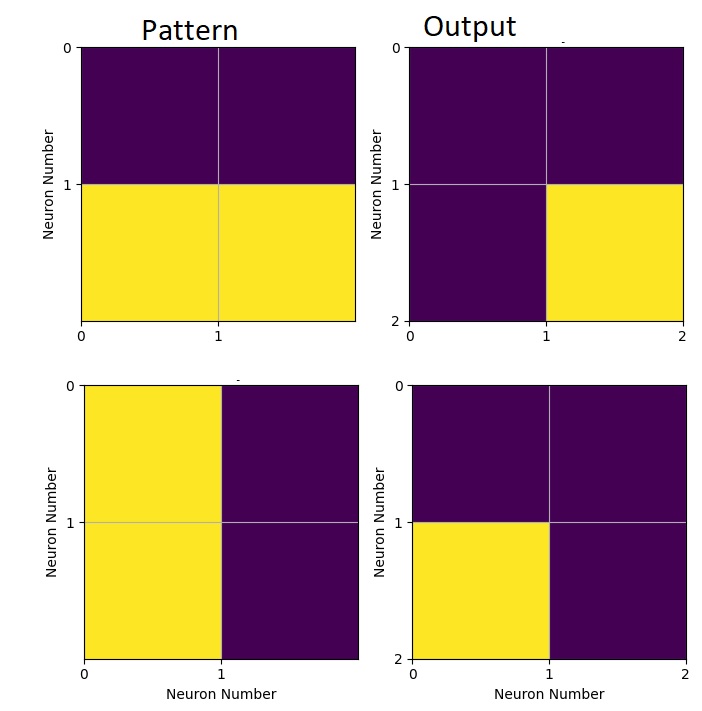
I was hoping for more progress, but I did not put in the work required. Over the holidays I’ve been mostly lazy. But anyway, I did manage to have the inhibitory neurons working. The project is very small and may seem even smaller to the untrained eye 🙂 I worked on a 2 by 2 matrix, with only 2 layers, one layer to receive the pattern the other layer to show the output. Second layer is what I call a compression layer since it’s doing a data reduction more or less like a complex cell would, a single cell responds to similar pattern such as a vertical lines .
Left showing the patterns, right showing the compression layers. Showing only 2 pattern but 3 are possible, the cross one is missing from this picture.
Why is this important at all ? Because otherwise a pattern eventually will spread all over the network in obscure ways. Say you have a pattern for letter A… some layers down the line you may find that pattern stored as an AAAAAAA chain without an inhibitory effect.
How important is this in the bigger picture ? Not nearly enough, but now I can move onto the next big issue, make the network learn based on feed-back… What does that mean ? it means that now I should have a 3rd layer which should associate 2 unrelated patterns as being the same, based on my feed-back.. take the two pattern above, a vertical line and a horizontal line. A third layer should have a single neuron firing whether the vertical line is showing or the horizontal one is… because I say so, you see 😀
From my many simulations I concluded that inhibitory neurons (why in the world are they called Interneurons?) have to be there to stop information replicating endlessly on all neurons. So each inhibitory neuron will prevent the same information to be replicated in the cluster of neurons governed by a particular inhibitory neuron.
They also determine the level of discrimination, the smallest information that can be classified will depend on the number of inhibitory neurons. The more inhibitory neurons the smaller the information that can be classified, more discrimination. If one would want to have a pixel wise discrimination the number of inhibitory neurons should equal the number of pixels.
There is an additional role, to regulate frequency, but I cannot test this one since my frequency is fixed and because of that I don’t need this role added to my code.
On the update front… well, I learn every day something new, mostly by discarding ideas that don’t fit the general algorithms. I’ve reached a point where I need to code all the new ideas and see actual results. I cannot go further till I get a better understanding of the impact of the new ideas.
I’ve settled some concept that were somehow in limbo, what is the relation between the information contained in two different dendrites of the same neuron, or how many layers should my network contain, to accomplish a certain task.
But some older problems came back into focus… what is the reach of a single neuron ? Answering this question is not really a must for the layers doing data classification but it gets important for what I call decisions layers … Decision layers can be viewed as output layers for simple networks, but in my model they can be used to sandwich classification layers , that means I can have more than one in a network. For the next 2 weeks I’ll be working only on programing the new concepts.. see what I get. What I should get is identifying letter A at different positions and sizes as being letter A, and not a different pattern, on a 252 x 252 matrix…
I’ve spent already too much time on this topic with no real insights. Most of papers I read said something along the lines: they link together to overcame inhibition. But perhaps is not meant to be taken at face value. They can overcame inhibition only by being active, but if they are already active, what do they overcome then ? Moreover, we say they are inhibited, but in fact they are active ?
Assume such a dendritic structure: D(S1, S2), where S1 and S2 are 2 synapses. Assume S1 and S2 are not able to activate dendrite D by themselves and they need and additional S3 for the dendrite to become active and activate generic Neuron N1. That means the neuron providing the synapse S3, lets call it N2 has to fire first. This way may be possible to establish directionality as long as N1 does not link back to N2. But what is “direction”… Hubel and Wiesel experiments did have direction but in real life light is always there.. Could direction be the constant movement of the eye ? Even so, why would direction be important ?
Can’t find a believable reason for having a true inter-layer link. When I say “true inter-layer”, I’m trying to discard the possibility where neurons actually link in a feed-forward like network, but where a biological layer is actually made of many “neuronal” layers..
I’ve spent most of my time reading about inhibitory neurons. I can’t say I found the holy grail. Too much data to sift through, so still searching. However, I tried also to do some theoretical simulations, went through about 20 models but nothing seemed to make sense. I also created a smaller version of my AI coding with just 3 neurons, two of them excitatory and one inhibitory. They obviously (only in hindsight obvious) can’t do inhibition in all cycles, they do inhibition only in 50% of the cycles, moreover, if I allow excitatory neurons to bind among themselves in a circular fashion (A binds to B and B binds to A) then in some cases they will will keep exciting each other in the absence of an outside input. A is active and will activate B and then B is active and will activate A. In hindsight, also obvious :-)..
But what are the roles an inhibitory neuron can play ?
they should adjust the frequency of firing. Here I have to say that I don’t understand why people are still considering firing rates as being meaningful., Firing rates dependent of the intensity of the stimulus, if I shout louder there is an increase in firing rate but I can’t understand things faster. So information at some point has to be slowed down to integrate with the rest of the information. For example if I say a word in which some of the letter are louder then I would lose the meaning of the word because some sounds will arrive and be process faster than the rest of the word. But maybe I’m missing something.
they should provide feedback from other area, but feedback can come also from regular neurons.
in my model I need them to extinguish excitation propagating through all the network, stopping the circular activation from A to B but I can’t find a reasonable way of doing this.
They should also act as a secondary mechanism in data analysis, the first mechanism being the normal neurons. To be more precise, they should be able to prevent the same pattern being learned by more than one neuron, at least this is one of my working hypothesis. How to do this has remained elusive so far… Another way to do this, through topological means, is still in the cards, but I have made not progress on this front either.
Another function could be, to force dendrites to make more synapses, at least in some cases, where the inhibitory neuron binds to dendrites and not to the neuron body.
In summary I have no working hypothesis on what the inhibitory neurons do.
A bit of a good news is that I found this course online from MIT, through their MIT OpenCourseWare: Sensory Systems, held by professor Peter H. Schiller. That’s an excellent course, lots of information, well structured and well presented. Many thanks to MIT for allowing free access to such great resources.
I added in the inter-layer neurons, hoping to solve some problems related to network transmission. Basically, because I don’t use full connections and because the neurons have to find their partners by themselves, I ended up with some non-trivial problems, if neurons are too far away on a 2D surface, they can’t find each other, so I thought I’d use other “inter-layer” neurons, to link them..
Adding inter-layer neurons did not help with long range connections but it did do an interesting thing, now it can reconstruct learned pattern using only parts of the patterns, some sort of a localized Hopfield network. Running a pattern many times eventually excites other patterns from the surrounding neighborhood, and, at the extreme, it excites all the network… all layers.. a total confusion… That’s the reason I need inhibitory neurons, to stop that uncontrolled excitation.
Anyway, this new observation, doesn’t help me at all. Over the weekend I watched some youtubes on neuroscience looking for inspiration .. very disappointing, there is an inflation of scientists trying to feed their families. So I decided to restrict my feed to well established universities, other talks promise much and deliver nothing. Now I’m watching the 12 lectures from Allen Institute: Coding and Vision 101.
So where I am at ? I can detect lines of some orientations, not all, but then I can’t link lines of the same orientations to a single neuron in the next layer because they are far apart and I build the network in the assumption the neurons link to neurons close by, don’t travel the world to find their pair. For long range links I was envisioning the use of inter-layer neurons … Even if everything would work perfectly, I still don’t see the next step, in the brain, simple cells link with multiple complex cells responding to the same type of signal… to what purpose ? How does that help in understanding the shape of an object ? Are they there just for invariance some sort of pooling to account for different positions on a surface, and basically have nothing to do with shape recognition ?
I have made some serious advances with my AI. Now I have definite pattern learning + pattern discrimination = pattern recognition. No doubts anymore, that this is working, but I also know that this is only the very first 0.1% of the development needed to truly claim a different type of AI – the Hebbian AI..
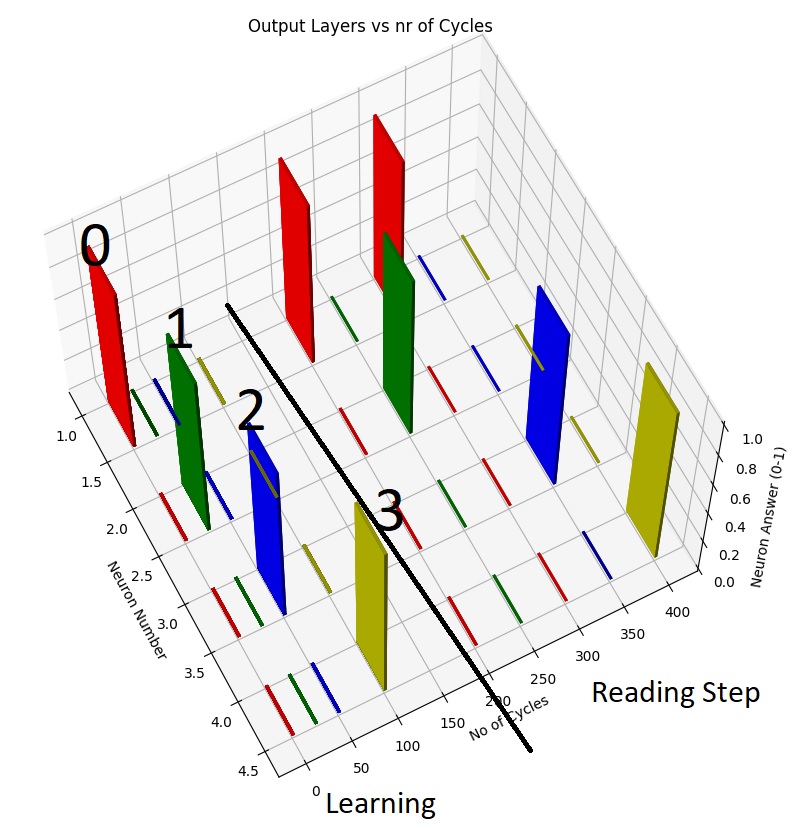
Here is the most relevant data:
First we have the learning step, before the black line. each pattern will activate a different neuron from the output layer, I only use 4 output neurons here. Then after the black line I “read” the patterns again, expecting that, the same pattern to light up the same output neuron.
I’ve also created a some sort of graphical interface and made a video with the whole process:
I have tested the code with 19 different patterns and 1 of the 19 patterns was misunderstood (letter M is sometimes confused with letter H), you can see it on the video. That was to be expected, at some point, some patterns, are going to be misunderstood. How many patterns can it learn ? All possible patterns within that matrix (25 by 25 pixels), but as more patterns are added more misunderstandings should occur. Why ? because I don’t really have what in current AI is called “feature extraction”… I only have a single feature extracted, the whole pattern. This works with basically one (1) hidden layer and the extraction is made by the output layer…
This is also observed in the fact that as you go with more and more pattern learning, the learning process, becomes more difficult, it take more cycles to be learned. This should not happen with more “feature extraction” along the way… Learning should become faster, as more an more small pattern become common among the bigger patterns.
Any way this is a big achievement and a proof of concept, even if in infancy.
What’s next ? Of course feature extraction… My first target is to have a big line learned and then a smaller line be recognized as the same “line”. Right now, the smaller line pattern is considered an incomplete pattern and blocked from reaching the output layer. How am I planning to go ahead ? Well, I have wondered for a long time, why our brain, has neurons that bind among themselves within the same “layer”. I cannot find information showing differences between neuron that bind to neurons from the same layer and neurons that bind to neurons from a higher layer… They appear to be the same… I don’t know the ratio.. how many bind intra-layer, how many bind to the next layer. Do they have the same learning rate ? Do they form as many/as few dendrites/synapses ? Do they have a shorter axon from the beginning ? are they attracted the same by the Nitric Oxide (retrograde signalling) ? Is mirroring happening only for inter-layer binding neurons or it also happens to inter-layer binding neurons ?
( Mirror neurons are neurons that fire both when an individual performs an action and when the individual sees[14] or hears[15] another perform a similar action from wiki).
So there are many many unknowns, not sure about the time frame I’ll be able to put them all together… I’m hoping to have something working by the end of the year… but who knows, I may decide to take a more brute force approach and use what I already have, multiply the single feature extraction, but that should prove slow, inefficient and inflexible… Anyway, small line/big line – here I come !!!!
“Cells that fire together wire together.” – see it on wiki
A Hebbian AI is the term I used to describe my AI project, yet, what a Hebbian AI might be is not clearly defined. The mathematical description is extremely limited and is totally different from what I’m using for this AI.
SO what do I mean by Hebbian AI ?
it has a learning algorithm based on: ” Cells that fire together wire together “, so it is not using regression for learning, so no back-propagation function. It does not do ANY kind of regressions with all the downsides it brings.
The network is made WITHOUT connections. Connections between neurons are made dynamically. There is both creation and destruction of connections.
The neurons are using only 0 and 1 as responses, so every type of signal can be correlated and understood, for example an IR sensor can be integrated with an audio signal … They are both treated the same.
Possible advantages over current AIs:
It could be way faster for some tasks. That remains to be determined with some sort of benchmarks. So far the code is in Python with zero optimization… no multi thread no GPU use.. nothing. Even so, for what it does at this moment, should still prove faster than whatever sophisticated AI out there.
It can immediately integrate all kind of data, visual, audio, pressure, IR, 2-3 video inputs .. everything.
It has causality, as far as causality can be determined from observable data, built in.
It has temporal awareness, so it matters what is learned first
Understanding is probabilistic, sort of a Bayesian learning
Possible dis-advantages over current AIs:
It does not do regressions, so it should not be able to do some task, that are possible today with current AI.
It is somehow more imprecise (no values between 0 and 1).
It can’t be made totally parallel when computing neuronal responses… many processes need to remain serial (so postsynaptic neuron cannot fire before the pre-synaptic neuron ).
I’ll update this article once I understand more :).
The bad news first. Seem my previous post was some sort of a random luck error. The code did not behave as expected, but I was too exited anyway, and rushed to post it. (not that anyone read this blog..lol). So I went back to the drawing board working only with enough data to have some meaning but otherwise the simplest data possible: [1,0,0,1]. Then after I was convinced everything worked well (enough..lol) I moved onto a bit more complex data.. a 5×5 array with two patterns:
a right line /
a left line \
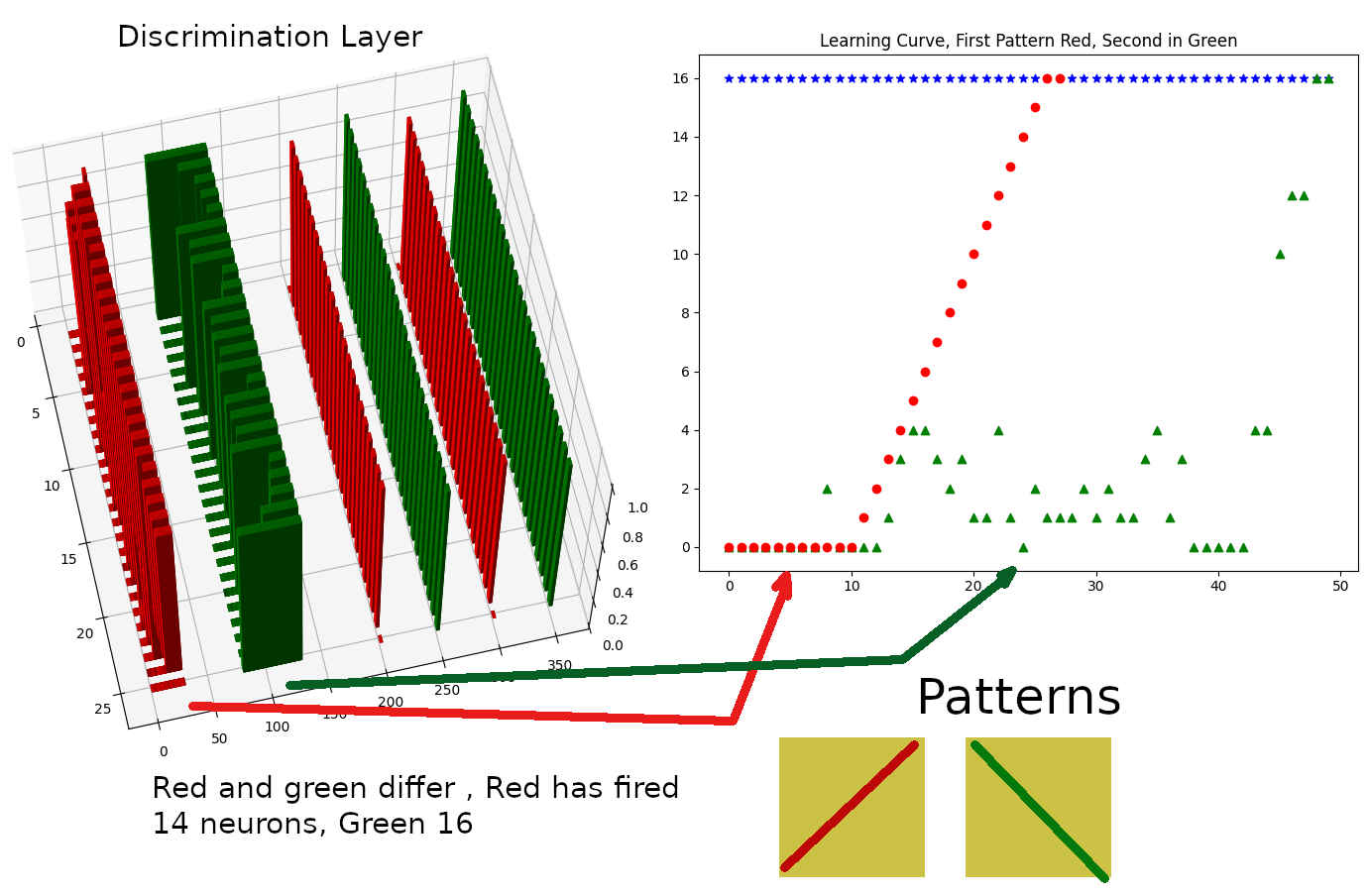
Then after even more work, mostly figuring out how my important variables (number of connections, filter size, learning factor and so on) affect the results. I am no where near understanding all the subtle influences are having, but I have some important rules to guide me. Last layer has to have all neurons firing to decide when something was learned, and read data from the discrimination layer (second to last). Then the magic happened.. I was able to repeatedly see the same difference between the two patterns: \, /.
Also, as predicted, I needed to see a learning curve (which was not happening in my previous post, there was no apparent learning, the signal would just drop)
Here’s the data:
Learning two patterns: / and \. The patterns are 2 png files of 5 by 5 pixels each. Left graph showing the discrimination layer, second one (number of cycles vs active neurons in the learning layer (last layer in this configuration)
How confident am I that this is not yet another fluke ? Well, is not 100%, that’s for sure, I need to run more (simple) patterns and then more complex patterns to get to 95% confidence :). I’ve changed my mind too many times and now I’m more skeptical than ever.. even when things do go as predicted.
My set up so far: Input Layer (5 by 5 matrix), 2 Hidden Layers (5 by 5) and an Output Layer (4 by 4), a total of 91 neurons. Output Layer = Learning Layer, Last Hidden layer acts as a discrimination layer.