I implemented more sophisticated mechanisms for inhibition… Now an inhibitory neuron is identical in behavior with a regular neuron.
So I implemented 2 mechanism, 1) the inhibition would be at the neuron body and 2) the inhibition acts directly on synapses. None of them makes any sense.. When inhibiting the body (1), synapses are not protected by LTD/LTP effect => the net effect is a decrease in the firing rate and there is no permanent inhibition for any patters.. When inhibition hits, couple of activation cycles are skipped so you have patches of decreased frequency of firing alternating with no firing. When inhibition is at synapse level, I end up only with skipped activation cycles, the firing frequency remains the same since synapses are protected by LTP/LDP effects..
In both cases I see no use for that delay in activation, because is not a single patterns that is delayed, all of them are. The separation between patterns is not great (couple of cycles apart), the problem comes also from inhibitory firing with very low frequency. Their activation depends on the activatory neurons, which have decreased activation themselves as you go up in the layer number.
I sort of defined my “objective” function for a synapse:
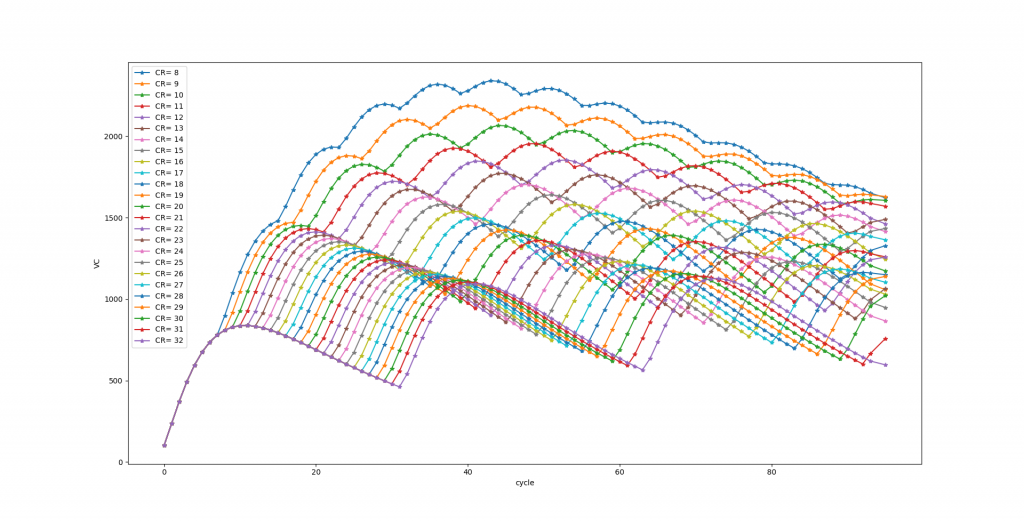
I also defined LTD and LTP, I initially believed they are just the fitting event for the objective function, but it seems they have multiple roles .
I made a lot of progress but still no “significant” progress..