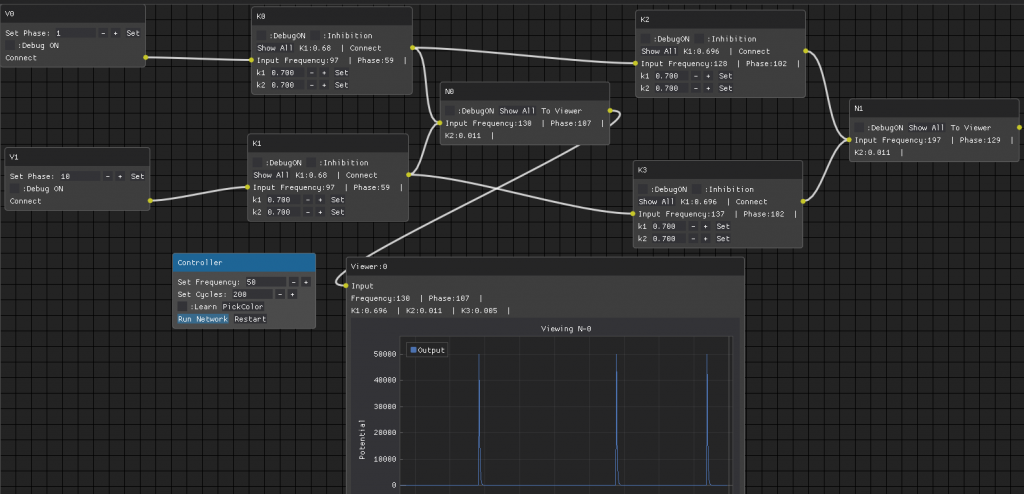
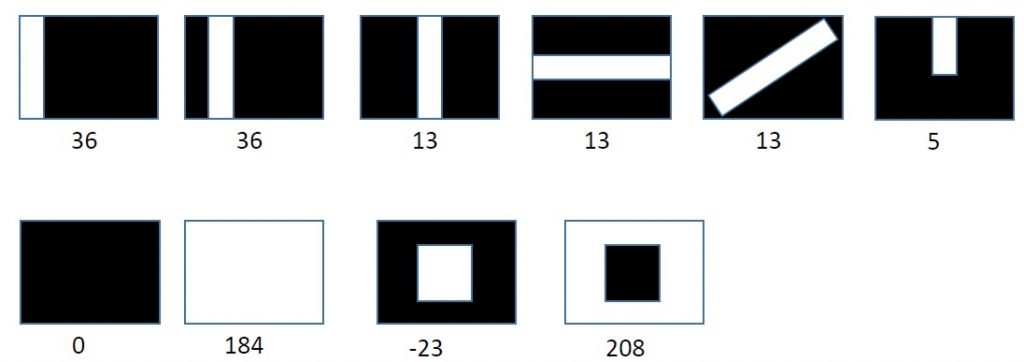
I coded some parts of the retina circuitry, now I have receptive fields, but still no color vision. Receptive fields are not as selective as they could be, but should be enough for now. Images are transformed to gray because I found no easy way to add in RGB data.
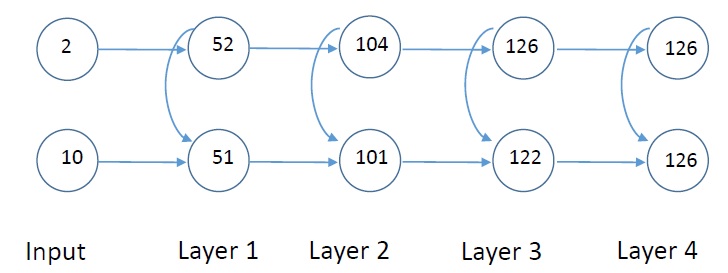
I also did some simulations to understand CA1 region but I still see no point in that complex arrangement. I did find something useful, a way to reduce phase difference. My focus was to get as much phase difference as I could, but then I realized that I also need to reduce the phase difference, somehow. So after 4 layers, with current set up, I get the same phase.
Anyway I one again got stuck in dealing with frequency. Different frequencies start from the receptor, eventually break synapses and I found no way to have a single frequency at time t for all regions from the visual field.. Unless I impose a single unchanging frequency. As far as I can tell frequencies play an important role so there should be a way to let them in. It seems the amacrine cells correlate frequencies for the bipolar cells they modulate, but I could not find this to be true in literature. There is very little information regarding amacrine cells.