
Progress has been slow for a while, but after a certain development threshold was reached, things have started moving faster. I now have a good release candidate for my neuron code. I also spent a lot of time reading and doing theoretical calculations. While the Neuron can be well described in mathematical terms, the network is too complex to describe in mathematical terms. The code can handle now 2D images, with at least thousands of cycles and at least thousands of neuron into the net. Perhaps more, I have not tried. Speed is not limiting me at the moment, 1000 cycles with 535 neurons took 20 seconds to finish, so I’m delaying any speed improvements for now, I was planing moving parts of code to C but other things are more important for now.
So what is new ? LEARNING hand written numbers from images.
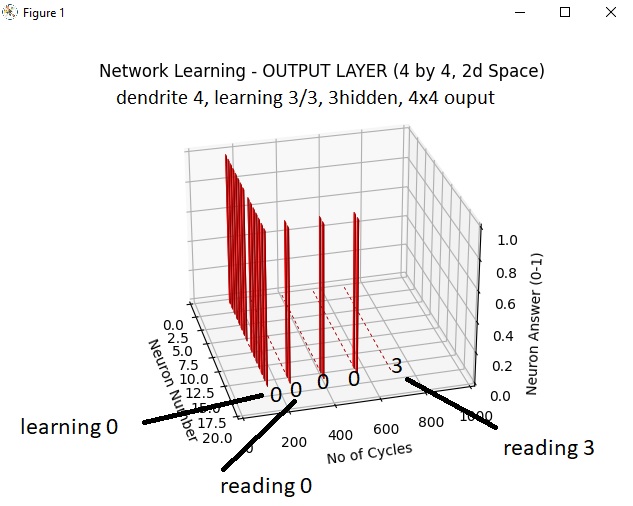
The output layer is a 4 by 4 matrix, but neurons are presented on a single row. All output neurons have a 0 / 1 response. After 150 cycles learning number 0, all neurons have “learned” the number and I was expecting all neurons to light up. They do, on certain configurations, but here one is off. After the initial process, I fed the network more images (different images) of number 0 (zero). I expect common features to be kept and at some point to obtain only a single output neuron in an active state, rest of them to be off. In the image above I’m showing some preliminary results where I get results only for different images of number zero, and I get no result for images of number 3. For training I’m using a very small MNIST data base with hand written numbers. What about CNN ( Convolutional Neural Networks ), pooling and such ? I’m using none of those. The image if fed directly into the hidden layer neurons. I worked for a bit to implement a receptive field algorithm. While I believe that to be a very useful and smart way of reducing complexity, I don’t believe is needed for simple images like this.
What’s Next?
Learning all numbers and letters, at the same time. I have hoped that the current set up will allow for at least 2 numbers learning at the same time, but I had no success so far. Keep in mind that the network has many parameters that need to be optimized, such as number of synapses (connections per neuron), number of hidden layers, neurons per layer, learning factor and so on. Right now I’m using this configuration: Input layer a 25 by 25 matrix with 3 hidden layers (25 by 25) and a 4 by 4 output layer.