
Running actual images where the background is a thing put all my theories on ice.. I first realized that when I have many synapses for a neuron and few for another, it modifies the activation phase …d’ooohh… and I had to bring back my old nemesis, frequency. Frequency means now that a neuron can receive multiple pre-synaptic inputs before it fires once. I discarded this idea not only because it complicates matter, but I though this should not be the default mechanism, because would be a waste of energy.. Besides with thousands of synapses is not very likely for a neuron to wait for a secondary activation to do a time summation for activation. Anyway, I thought by bringing frequency back, the very bright neuron would win the inhibition battle.. Not likely, multiple synapses would still win. The consequence is that the background is selected instead of the foreground.. because it’s big 🙂 . How are CNNs dealing with this issue ? I’ll have to look into it. I have thought long and hard… I see no way around this, because in a way is the expected behavior given my algorithms… But, as with many other problems, I have a general solution.. I’m going to ignore it… I’ll chose a very low intensity background, I’ll avoid using both ON and OFF bipolar cells from the receptive fields and go with this. Sure I can’t have real images now, but maybe along the way I’ll find a solution or a solution would present itself..
Going somewhere
All small parts seem to be working, I have gotten small invariance for position and size and now I’m working to put them all together and hopefully have some sort of object identification. Soon I hope, I’m still dealing with some bugs and some things are working for the wrong reason and perhaps I’m procrastinating too, because I’m afraid that I’m missing something and it will not work..
Why this uncertainty ? isn’t all math ? There is the deep issue that I don’t see how this is working … In small simulations I know for sure what I’m doing but after adding some complexity and multiple layers it’s impossible to predict how thing are going to turn out… much like the current AI algorithms. I’m sure Google team that released the “Transformer” algorithm did not see ChatGPT in the future. Imagine Google having exclusivity on the Transformer … being the only one with generative AI…
I’ve been thinking long and hard of what to do next, say I get to identify objects.. what next ? I have many unexplored ideas such as linking unrelated objects as being the same, such as “A” and “a” or even the sound of “A”.. But this is not adding much value to the whole. The value should only come from an AI that can “reason”.. can plan.. I found it impossible to make the AI algorithm understand things that don’t come from outside as information. If I were to say : “Move the mouse cursor 2 pixels to the left”, most difficult is “Move”… move is nothing, while the others are something.. How can I convey that IT should do something ? I can of course cheat, program in some key word, once detected the word “Move” will trigger a scripted action.. But that is zero value to my mind.. So in fact I don’t see a way past data processing (image identification, sound, anything that can be converted in some arbitrary numbers)…
Can it work as a chatbot ? No… ChatGPT is an anomaly in the world of AI.. I agree that our brain also relies on statistics but if some one says ” Move the mouse cursor 2 pixels to the left”, my brain does a lot of processing .. it has to identify that I’m the one that should do the action by analyzing the environment, the context.. Am I close to a computer ? I’m I the only one in the room ? Do I want to answer this request, is it in my best interest to do so ? Only after many processing I will do something…. ChatGPT avoids all this hard processing and relies on what has learned as statistics from examples to formulate and answer immediately. Still in some parts, we as humans, work as ChatGPT… respond with learned answers without any other type of processing .. In this context “learn” is an arbitrary association in between parts of information (aka symbols). Much like “A” = “a” ..
So after I’m done with object recognition, I will seek help, some sort of collaboration with whomever might be interested …
Frequency is trouble
I coded some parts of the retina circuitry, now I have receptive fields, but still no color vision. Receptive fields are not as selective as they could be, but should be enough for now. Images are transformed to gray because I found no easy way to add in RGB data.
I also did some simulations to understand CA1 region but I still see no point in that complex arrangement. I did find something useful, a way to reduce phase difference. My focus was to get as much phase difference as I could, but then I realized that I also need to reduce the phase difference, somehow. So after 4 layers, with current set up, I get the same phase.
Anyway I one again got stuck in dealing with frequency. Different frequencies start from the receptor, eventually break synapses and I found no way to have a single frequency at time t for all regions from the visual field.. Unless I impose a single unchanging frequency. As far as I can tell frequencies play an important role so there should be a way to let them in. It seems the amacrine cells correlate frequencies for the bipolar cells they modulate, but I could not find this to be true in literature. There is very little information regarding amacrine cells.
what is learning #2 ?
A way to receive data, a way to discriminate data, a way to store and retrieve, a criteria to select what should be stored for later retrial.
From all of the above steps as far as I can tell I only have the discrimination algorithms, which in fact depends on the received data and on the selection of what should be stored algorithms. So it’s incomplete or it lacks complete parametrizations.
I worked on data receiver, converting visual data (RGB pixel values) into data that can be accepted by the discrimination algorithm. For color discrimination just converting a number into a different number through some function is enough. But to detect lines of different inclinations, colors, dimensions.. that is not enough.. So I started implementing the “receptive fields” concepts from retina, with the ON and OFF behavior and center/surround. I have yet to find relevant details for implementation. So I guess is trial and error again. For example I have found no details of the size of the center vs surround. Small center, makes it hard for light to hit it, to hit only the center and not the surround, so ON centers are darker than expected and OFF center brighter… But this results in good discrimination for line inclination .. There are also contradictory information about horizontal cells .
I have looked at a way to store data, CA1 region from the hippocampal circuit seems interesting because of its configuration. But even the simplest simulation shows that a neuron cannot link back into itself… But maybe I’m missing something. Anyway that seemed like an interesting way to discriminate small similar patterns.
Data retrieval remains mysterious, it seems we retrieve data by recreating it in an altered version.
How to select data to be stored ? This is an area for which I have no idea… But for now this can be bypassed the easiest.. I tell the system when to store that data. The system stores automatically data that passes some abstract threshold, but there are trade offs with this approach, so in fact most of the data does not reach that threshold.
Anyway, “learning” remains open for debate.
My progress has been slow, there are things that I can do and I know how to do, but I lack motivation to do them because they don’t seem important. And then there is an infinite list of mostly poorly defined tasks.
a very small update..
I now have the code and the proof that my new learning theory works. I was very anxious till the very end because most of the time my theoretical predictions failed when put to the test. I would make a theoretical calculation, but using many approximations and when everything will be put into code and graphs, I would find some unpleasant surprises :).
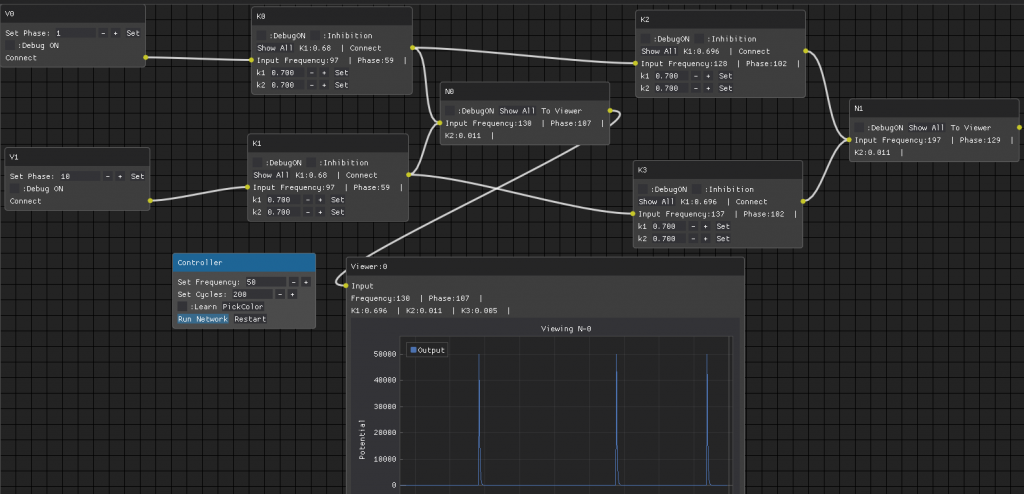
This is the set-up used for the 2 color separation. I spent couple of weeks adding this new GUI, so I can inspect each neuron in much more detail.. abandoning for now the complex GUI used for many neurons working in a complex network.
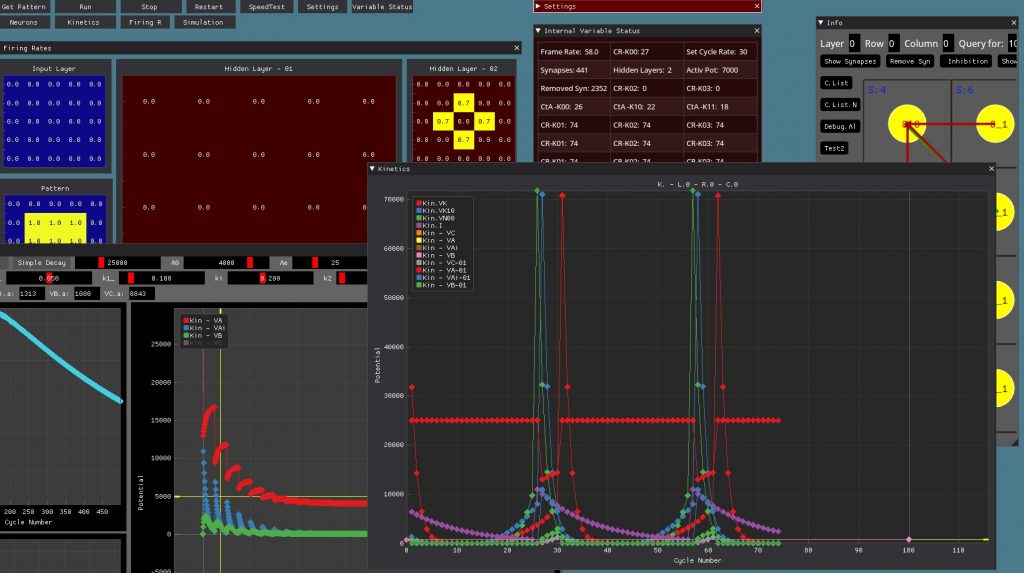
Next I want to separate multiple colors and create a proper presentation with couple of explanations perhaps … or maybe just a video showing the action…
Still haven’t solved the problem of “embedding” for colors… I have a function that takes as an input an RGB value and converts it into a “phase” number, that can be used by the AI algorithm, but is not good enough because is not working for all colors… Some colors translate into very high or very low phase numbers so they cannot be used by the algorithm .. So I’m not sure yet how to show “learning” for all colors.. But more than 2 colors should be a good start…
Molecular descriptors, embedding and frequency
I was discussing how my friend used molecular descriptors and some form of backpropagation to find “similar” molecules for specific purposes. The process was similar or identical (if considered in general terms) with the “embedding” process in AI.. “Embedding” is supposed to convert a type of information in a different type so in the end apples and oranges can be compared. Restricting the output of e perceptron to 0 and 1 or -1 to 1 is also a way to make data comparable still an embedding problem.. Our brain seems to have found the ultimate embedding, transforming all data from all sources, in frequency (and phase) so everything can be compared.
I’m struggling with converting an image data (say RGB values) into something that can be used by the AI algorithm. If information is not converted “properly” (what’s proper is unknown) then the algorithm will fail to detect differences in the input data, fail to learn anything… which may actually be the reason why I spent so much time with no progress what so ever…
I’m still far away from showing anything concrete. My plan was to create a test program that shows how two colors can be learned, but I took a very very twisted approach and now I’m further away from my goal then when I started. Why ? Not sure.. Maybe I believe this is more complex than on paper ? Maybe I believe that even if this works is not proving anything ? So by observing my approach I must conclude that I’m getting ready for multiple problems which cannot be solved unless I understand very fast what the real problem is.. So I’ve been motivated only to construct more an more tools to better visualize the data and eliminate ambiguous options … and still hesitate to take more decisive steps.
what is enough ?
I’ve been making some unexpected progress, I found a learning mechanism which is both simple and reliable and integrate 100% with all of my other ideas. Now, I’m again building a small test to show learning of colors with 3 input neurons. It’s taking a lot of time because since I changed the code to incorporate more C/C++, parts of the code are not working properly or failing completely… So perhaps another week maybe two till I can show my idea in practice. All the test I’ve done so far are in a sort of a manual network, I link by hand neurons, initiate them one by one and such..
Anyway the problem I have now is when to stop “learning”.. The way it works now is as follow : the network learns by itself up to values, then if I want to separate patterns and learn them separately even further, I have to tell it to learn.. Learning behaves like dopamine or serotonin influx, so some constants are altered by an external (or different) mechanism.. Trouble is that this learning would go on till the very limits of the input data.. Assume we have a 10 synapse pattern.. While I see it as a pattern, if I decide, I could also go deeper (up to my visual acuity) with dissecting that pattern into smaller patterns… So I may be able to discard 5 synapses (points) from that pattern and consider they do not meet all criteria to be part of that pattern… And then to the best of my sensory perception I can’t find other differences among the remaining 5 synapses.. My AI does just that at this point… discards everything up to those 5 remaining patterns because I’m not sure how to define criteria that would stop it before reaching that very end.. So how do we know enough is enough ? How do we decide what to learn ?
Anyway, this is now a very very different problem than the ones I had so far.. The important point is that under clearly defined conditions the system has a mechanism of learning. This is all very new to me, so I may get some ideas later on. Right now I’m focusing on building the whole system back to its original functionality and building the color discrimination demo along the way.
What to “input” ?
I have based my learning mechanism on inhibition, it didn’t work. Inhibition favors complex patterns (multiple inputs) over smaller patterns, but we can learn both. Also Inhibition is a complex race, change frequency and the winner becomes hard to predict.
Next I tried using repetition as the bases for learning, frequent patterns will become favored over less frequent ones.. But this got me nowhere, within the limits of my system, everything eventually becomes well known pattern, because a learning variable cannot increase forever… so 2+ 2 is equally probable to be 2,3,4,5 and so on. So when everything is learned, nothing is..
This brings me to this topic… The input should provide the information, but how to encode / decode it. I have 3 parameters that I use to send information to the network:
Frequency, Phase and Sequence (sometimes I refer to sequence as timing ). So far I just made abstract assignments, I mostly kept Frequency constant and abandoned Sequence a while back. So I used only Phase like, 3 means this, 4 means this.. Nothing concrete. Meanwhile forgetting what 3 meant … This seems chaotic because only in retrospect I realized what I was doing… I just focused on “learning”… using simple patterns of a line of 2 pixels or 4 pixels, linear or cross.. But learning has to be better correlated with the input. So lately I’ve been working in actually converting a real image in an input, rather than creating abstract 0/1 patterns because I’m sure there are thing I’m missing and the network may not be receiving actually information through the input. But I still don’t know what I’m doing. I converted RGB data to LMS and randomly made input neurons as favoring RG or B frequencies. I liked the idea of LMS because I don’t want zero input values for any color, but I don’t like that for some colors the output of LMS is extremely small, that means the network will be blind to those colors, but it doesn’t matter that much for now, I will work only with colors that give adequate response, maybe even dropping the conversion to LMS since that has its own problems.. Having neurons that respond differently to colors creates chaos instantly but maybe this is what I need to move things forward …
“Learning” is still eluding me. Even without LTP/D or without inhibition there should still be a leaning mechanism, the network should learn something.. good/bad doesn’t matter. A set of variables should change because of a given pattern and remain so… In my case, many variable change, but they change back or getting altered by new patterns so much so that there is no more a correlation between initial pattern and some variables… I believe the problem comes from the fact that I don’t have a mechanism for Phase learning.. Phase is easily discriminated but I don’t see how I could make a neuron phase specific. So still in the dark but making progress by constantly discarding thing that don’t work 🙂
Inhibition brings order to chaos
I knew this should happen but only now I could see it in my simulations.. The question is now, how to get to it without me manually changing the inhibition value ? Whatever I tried, failed so far… But this is important otherwise I get random results in all the layers..
Some Updates
I have reached some limits using Python, Tkinter and Matplotlib and I had to switch to DearPyGUI and converting more code into C through Cython. This took awhile but results are good for now, I did not realized how slow was Matplotlib with plot drawing..
Now that I have more tools to see what’s going on, I realized that LTD/P effects are more complex than I envisioned.. if a neuron responds faster to an input signal (say because of an LTP effect, or higher frequency input signal or because it has more connections or because is less inhibited ) then it immediately alters the flow of information … Weak synapses become oriented resulting in (as of now) unpredictable results.
Inhibition is also more complex, a neuron under inhibition could be forced to wait for the second activation signal to become activated, but I’m still not sure of how to do it… Right now the neuron remains in an undefined state when inhibited… Is not firing but is not in re-pause either, I haven’t decided what to do with it..
With more speed I could let the synapses form and break indefinitely and it became clear that there are strong synapses defined by data flow and weak synapses that form and break immediately, about 10% are weak synapses..