
After many trials and many grandiose ideas, I simplified everything to bare minimum. Only a single neuron. Fix that part first. I gave up on sophisticated connections, but those functions are still available, gave up on complex distributions. And here I am… a single neuron + 3 input Neurons. The input neurons do almost nothing, they are there to establish input connections with “real” neurons. And without further due, this is it:
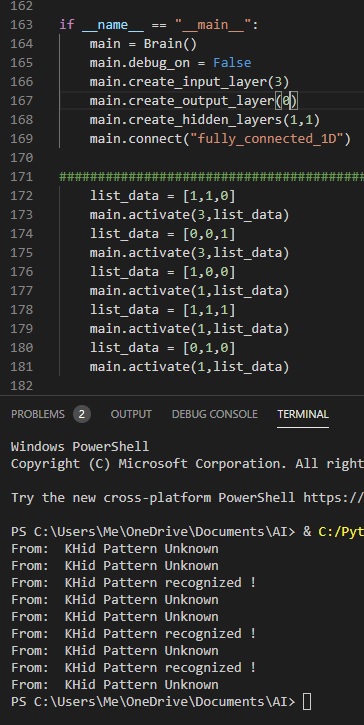
I have a pattern of 3 digits but the pattern can be infinite. The learning part comes from repetition. See the same pattern twice and that is it… the third time the pattern is recognized. I taught the AI 2 patterns [1,1,0] and [0,0,1]. Then I asked it for other 3 patterns: [1,0,0], [1,1,1] and [0,1,0]. I was hoping for a “Pattern Unknown”, all over, but instead I got an unexpected: “Pattern recognized !” for pattern [1,1,1]. So if it’s composed of two know patterns, is still considered known.
Keep in mind: NO BACK-PROPAGATION.
I went for an actual neural net, meaning many neurons connected somehow. The full connection (each neuron with each neuron), proved useless, all neurons became symmetric with same output. So next step is to go for an asymmetrical connection between neurons. I’ll first try the asymmetrical_1D and then asymmetrical_2D, and eventually get back to random spherical distribution.